
Llama 4とは?
Llama 4は、Meta(旧Facebook)が2025年にリリースしたオープンソースの大規模言語モデル(LLM)です。中でもLlama 4 Maverickは、128のエキスパートモデルを組み合わせたMixture of Experts(MoE)アーキテクチャを採用しており、総パラメータ数は4000億を超える大規模モデルでありながら、推論時に使用するアクティブパラメータは約170億に抑えられています。
最大の特徴は「完全オープンソース」であること。商用利用を含むライセンス(Llama Community License)で公開されているため、個人事業主やフリーランスが自分のPCでローカル実行し、API料金ゼロで利用できます。ChatGPTやClaude APIに月額課金する必要がないため、コスト意識の高いフリーランスにとって有力な選択肢です。
2026年現在、OllamaやLM Studio、llama.cppといったローカル実行ツールが成熟し、以前と比べてローカルLLMのセットアップは格段に簡単になりました。この記事では、Llama 4をローカルで無料実行するための必要スペック・手順・活用法を日本語で解説します。
Llama 4の主な機能
マルチモーダル対応
Llama 4 Maverickはテキストだけでなく、画像入力にも対応したマルチモーダルモデルです。画像を含むプロンプトを処理し、画像の内容を説明したり画像に基づいた質問応答が行えます。ローカル実行でもこのマルチモーダル機能を利用できますが、画像処理時はVRAM消費量が増加します。
長文コンテキスト処理
最大100万トークンのコンテキストウィンドウに対応しています。長文ドキュメントの要約、複数ファイルの横断分析、長編コンテンツの一括処理が得意です。ただし、ローカル実行時はVRAM容量の制約によりコンテキスト長が制限される場合があります。
コード生成と分析
プログラミング言語の生成・解析能力が高く、Python・JavaScript・TypeScriptなど主要言語のコード生成、デバッグ、リファクタリングに対応します。フリーランスエンジニアがコーディング補助として活用できる水準です。
多言語対応
英語を中心に、日本語を含む多言語に対応しています。ただし日本語の精度はGPT-5やClaudeと比較すると一段落ちる点は認識しておく必要があります(詳細は後述)。
Mixture of Experts(MoE)
128個のエキスパートモジュールから推論時に必要なものだけを選択して処理する仕組みです。総パラメータ数に対してアクティブパラメータ数が少ないため、従来の同規模モデルと比較して計算リソースの効率が良いのが特徴です。
必要スペック(GPU/VRAM)
ローカルでLlama 4を動かすには、GPUのVRAM容量が最も重要な要素です。モデルサイズと量子化レベルによって必要VRAMが変わります。
| モデル | 量子化 | 必要VRAM | 推奨GPU |
|---|---|---|---|
| Maverick (Q4_K_M) | 4bit量子化 | 約48GB | RTX 4090×2 / A100 80GB |
| Maverick (Q2_K) | 2bit量子化 | 約28GB | RTX 4090 / RTX A6000 |
| Scout (Q4_K_M) | 4bit量子化 | 約24GB | RTX 4090 / RTX 3090 |
| Scout (Q2_K) | 2bit量子化 | 約14GB | RTX 4070 Ti Super / RTX 3090 |
個人利用で現実的な選択肢は、Scout(約170億パラメータ)の4bit量子化版です。RTX 4090(24GB VRAM)1枚で動作し、日常的なテキスト生成タスクには十分な性能を発揮します。
Maverickを快適に動かしたい場合は、RTX 4090を2枚構成にするか、NVIDIA A100 80GBクラスのGPUが必要です。個人で用意するにはハードルが高いため、ScoutかMaverickの2bit量子化版が現実的です。
CPU(Apple Silicon含む)でも動作しますが、推論速度は大幅に低下します。M4 Max(128GB統合メモリ)であればMaverickの量子化版も動作しますが、GPU実行と比較して5〜10倍遅くなります。
ローカル実行手順
Ollamaでの実行(最も簡単)
Ollamaは最も手軽にローカルLLMを実行できるツールです。インストールからモデル実行まで数分で完了します。
1. Ollamaの公式サイト(ollama.com)からインストーラーをダウンロードしてインストール 2. ターミナルを開いて以下のコマンドを実行
ollama run llama4:scout
初回はモデルのダウンロードに時間がかかります(Scout Q4で約15GB)。ダウンロード完了後、対話型のプロンプトが起動し、そのまま日本語で質問できます。
Maverick版を実行する場合は以下のコマンドです。
ollama run llama4:maverick
Ollamaの利点は、モデルの管理・切り替えが簡単なこと、APIサーバーとしても動作すること、そしてGPU/CPUの自動検出により設定不要で動くことです。
llama.cppでの実行(上級者向け)
llama.cppはC++で実装された軽量な推論エンジンで、細かいパラメータ調整やカスタムビルドが可能です。
1. GitHubからllama.cppをクローンしてビルド
git clone https://github.com/ggerganov/llama.cpp cd llama.cpp && make -j
2. Hugging FaceからGGUF形式のモデルファイルをダウンロード
3. 以下のコマンドで実行
./llama-cli -m models/llama-4-scout-q4_k_m.gguf -p “日本語で自己紹介してください” -n 512
llama.cppの利点は、メモリ使用量の最適化、バッチ処理対応、そしてGGUF形式の幅広いモデル互換性です。デメリットはビルド作業が必要で、Ollamaと比較して手間がかかることです。
LM Studioでの実行(GUI派向け)
LM Studioはデスクトップアプリケーション形式のローカルLLM実行環境です。GUIでモデルのダウンロード・実行・パラメータ調整ができるため、コマンドラインに慣れていない方に適しています。
1. LM Studio公式サイトからアプリをダウンロード 2. アプリ内の検索バーで「llama-4-scout」を検索 3. 量子化レベルを選択してダウンロード 4. チャット画面でそのまま対話開始
LM Studioの利点は、直感的なUIと、複数モデルの切り替えが容易なことです。
料金
Llama 4のローカル実行は完全無料です。
| 項目 | 費用 |
|---|---|
| モデルのダウンロード | 無料 |
| Ollama / llama.cpp / LM Studio | 無料(OSS) |
| API利用料 | なし(ローカル実行のため) |
| 月額サブスクリプション | なし |
| 商用利用ライセンス | 無料(Llama Community License) |
初期費用としてGPU搭載PCが必要ですが、既にゲーミングPC(RTX 3090/4090搭載)を持っている場合は追加費用ゼロで始められます。
ChatGPT Plus(月$20)やClaude Pro(月$20)と比較すると、年間$240の節約になります。API利用が多いフリーランスなら、月数千〜数万円のAPI料金をゼロにできるメリットは大きいです。
メリット・デメリット
メリット
完全無料で利用できるのが最大のメリットです。API料金・月額課金が一切不要で、GPUさえあれば際限なく利用できます。
プライバシーが完全に確保されます。データは外部サーバーに送信されないため、クライアントの機密情報を含むドキュメントの処理にも安心して使えます。NDA付きの案件を抱えるフリーランスにとって、これは重要なポイントです。
オフライン環境でも動作します。インターネット接続がない場所でもモデルを実行できるため、出先での作業や移動中の利用にも対応します。
APIとして自分のアプリに組み込めます。Ollamaを使えば、ローカルでOpenAI互換のAPIサーバーが立ち上がるため、自作ツールやDify・LangChainとの連携が可能です。
デメリット
高性能GPUが必要です。Scoutの4bit量子化版でもRTX 3090/4090クラスが必要で、GPUを持っていない場合は初期投資(15〜30万円)がかかります。
日本語の精度はGPT-5やClaudeに劣ります。特に敬語表現、専門用語、文脈理解の面でクラウドの商用モデルとの差を感じる場面があります。
セットアップに技術的知識が必要です。Ollamaの登場でかなり簡単にはなりましたが、GPUドライバのインストールやVRAM管理など、一般的なSaaSツールと比較すると敷居が高いです。
モデルの更新は手動です。クラウドサービスのように自動で最新版に切り替わることはなく、新バージョンのリリース時に自分でダウンロード・差し替えが必要です。
日本語対応の現状
Llama 4の日本語対応は「実用レベルだが、クラウドモデルには及ばない」という評価です。
日常的な文章生成、メール作成、要約、翻訳の補助には十分使えます。ブログ記事の下書きや、簡単なビジネス文書の作成にも対応できます。
一方で、以下の場面では精度の低下が目立ちます。
- 高度な敬語・丁寧語の使い分け
- 日本特有のビジネス慣習に関する質問
- 日本語の固有名詞(人名・地名・企業名)の正確な認識
- 長文の日本語テキストにおける文脈の一貫性維持
改善策として、システムプロンプトに「日本語で回答してください」「敬語を使ってください」と明記すると、出力品質が向上します。また、Scoutよりも大規模なMaverickのほうが日本語の精度は高い傾向があります。
2026年時点での日本語能力をGPT-5やClaude Opus 4と比較すると、体感で70〜80%程度の品質です。英語メインで使いつつ、日本語は補助的に利用するのが現実的な活用法です。
クラウドAPIとの比較
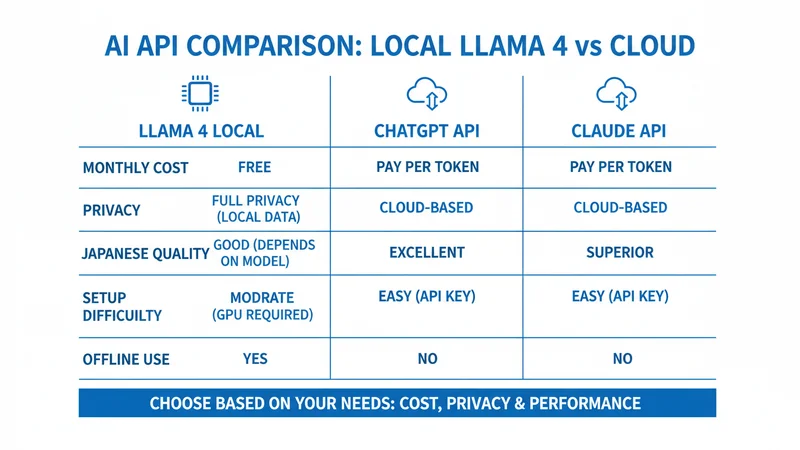
ローカル実行とクラウドAPI(ChatGPT API / Claude API / Gemini API)を比較します。
| 項目 | Llama 4(ローカル) | ChatGPT API | Claude API |
|---|---|---|---|
| 月額費用 | 無料 | 従量課金($2〜15/100万トークン) | 従量課金($3〜15/100万トークン) |
| プライバシー | データ外部送信なし | サーバー送信あり | サーバー送信あり |
| 日本語精度 | 中〜中上 | 非常に高い | 非常に高い |
| 応答速度 | GPU依存(速い〜遅い) | 常に安定して高速 | 常に安定して高速 |
| セットアップ | GPU・環境構築が必要 | APIキー取得のみ | APIキー取得のみ |
| オフライン利用 | 可能 | 不可 | 不可 |
| カスタマイズ | ファインチューニング可能 | 不可(API経由のみ) | 不可(API経由のみ) |
コスト重視のフリーランスには、ローカルのLlama 4が合っています。月間のAPI利用量が多い場合、クラウドAPIの従量課金は数千〜数万円に達するため、ローカル実行のコストメリットは大きいです。
一方、日本語の品質を最優先する案件(クライアント向け文書の作成など)では、GPT-5やClaude APIの利用が安定します。
おすすめの使い分けは「下書き・ブレストはローカルのLlama 4、最終仕上げ・クライアント提出用はクラウドAPI」です。
よくある質問(FAQ)
Q. Llama 4を動かすのに最低限必要なPCスペックは?
Scoutの2bit量子化版であれば、RTX 3060(12GB VRAM)でも動作します。ただし出力速度は遅く、快適に使うにはRTX 4070 Ti Super以上を推奨します。CPUのみ(Apple M4チップ含む)でも動作しますが、実用的な速度を得るにはGPUが必要です。
Q. Mac(Apple Silicon)でも動きますか?
動きます。M3 Pro以上のApple Siliconチップであれば、Scoutの量子化版が統合メモリを利用して動作します。OllamaはmacOS対応済みで、インストールから実行まで5分程度です。M4 Max(128GB)であればMaverickも動作しますが、GPU実行と比較して速度は遅くなります。
Q. 商用利用は可能ですか?
可能です。Llama Community Licenseの条件下で商用利用が認められています。月間アクティブユーザー7億人以上のサービスでの利用には別途ライセンスが必要ですが、フリーランスや中小企業の利用であれば問題ありません。
Q. ファインチューニング(追加学習)はできますか?
できます。自分のデータでモデルを追加学習させ、特定のタスクに特化させることが可能です。LoRA(Low-Rank Adaptation)を使えば、消費者向けGPUでもファインチューニングが行えます。ただし、ファインチューニングにはVRAMの追加消費とデータ準備の手間がかかります。
Q. ChatGPTやClaudeの代わりになりますか?
用途次第です。英語のテキスト生成、コード生成、要約タスクではクラウドモデルに近い性能を発揮します。日本語の高品質な文章生成やマルチモーダルの高度な利用では、GPT-5やClaude Opus 4が優位です。「完全な代替」ではなく「併用」が現実的です。
活用事例
ブログ記事の下書き生成
Llama 4をローカルで動かし、ブログ記事の構成案と下書きを生成するフリーランスライターが増えています。APIコストがかからないため、何度でもプロンプトを試行錯誤でき、最終的にGPT-5やClaudeで仕上げるワークフローが効率的です。
クライアント文書のプライバシー保護
NDA付きの案件で、クライアントの業務データを含むドキュメントを処理する場面では、ローカルのLlama 4が最適です。データが外部に送信されないため、情報漏洩リスクがゼロになります。契約書のレビュー補助や社内文書の要約に活用されています。
自作ツールへのAI機能の組み込み
OllamaのAPIサーバー機能を利用して、自作のWebアプリやスクリプトにAI機能を組み込む開発者が増えています。ローカルで動作するため、API料金を気にせず大量のリクエストを処理できます。DifyやLangChainとの連携も可能です。
コーディング補助
フリーランスエンジニアがコーディング中の質問応答、コードレビュー、バグ解析をLlama 4に行わせる使い方です。Cursor・VS Codeの拡張機能からOllamaのAPIに接続し、クラウドAPIの代替として利用できます。
注意点
Llama 4のローカル実行にあたり、以下の点に注意してください。
GPUドライバは最新版を維持してください。NVIDIAの場合、CUDA対応ドライバのバージョンが古いとモデルが正しく動作しない場合があります。
量子化によるモデル品質の低下を理解してください。4bit量子化はフルモデルと比較して5〜10%の精度低下があります。2bit量子化ではさらに低下します。品質が重要なタスクには、できるだけ高い量子化レベル(Q4_K_M以上)を使うことを推奨します。
VRAMが不足すると、モデルの一部がCPUメモリにオフロードされ、推論速度が大幅に低下します。タスクマネージャーでVRAM使用量を監視し、他のアプリケーション(ブラウザの多タブなど)と競合しないよう注意してください。
Llama Community Licenseの利用規約を確認してください。オープンソースですが、完全に制限がないわけではありません。利用規約に沿った使い方をする必要があります。
モデルファイルのサイズが大きい(Scoutで約15GB、Maverickで約50GB以上)ため、ストレージの空き容量を確保してください。SSDに保存することで読み込み速度が向上します。
総評
Llama 4のローカル実行は、「コストゼロでAIを使い倒したい」「プライバシーを完全に確保したい」フリーランスにとって、2026年時点で最も現実的な選択肢です。
Ollamaの登場により、かつてはハードルが高かったローカルLLMのセットアップが劇的に簡単になりました。RTX 4090を1枚持っていれば、Scoutの4bit量子化版が快適に動作し、日常的なテキスト生成・コード生成タスクに十分対応できます。
日本語の精度はGPT-5やClaude Opus 4には及びませんが、下書き生成・ブレインストーミング・社内文書の処理など、完成度を最重視しないタスクには実用的です。「ローカルで下書き、クラウドで仕上げ」のハイブリッド運用が、コストと品質のバランスが最も良い使い方です。
GPUの初期投資を除けば、ランニングコストが完全にゼロという点は、月額課金やAPI従量課金が積み重なるクラウドサービスにはない圧倒的なメリットです。年間で数万円〜数十万円のAPI費用を節約できる可能性があります。
まとめ
Llama 4のローカル実行は、フリーランスのAI活用コストを劇的に下げる手段です。
- 完全無料・プライバシー確保のAI環境を自分のPCに構築できる
- Ollamaを使えばコマンド1行で実行開始
- Scoutの4bit量子化版ならRTX 4090(24GB VRAM)1枚で快適に動作
- 日本語は実用レベルだが、重要な文書はクラウドAPIと併用がおすすめ
- API料金ゼロで大量のテキスト・コード生成が可能
まずはOllamaをインストールして「ollama run llama4:scout」を実行してみてください。5分後にはローカルAI環境が手に入ります。
[AFFILIATE_LINK_OLLAMA]
GPUを持っていない方は、まずクラウドのAIツールから始めるのも良い選択です。ChatGPT、Claude、Geminiの無料プランでAI活用の効果を体験してから、ローカル環境の構築を検討してみてください。


コメント