
- Stable Diffusion 3.5とは?
- Stable Diffusion 3.5の主な機能
- Stable Diffusion 3.5の料金
- Stable Diffusion 3.5のメリット
- Stable Diffusion 3.5のデメリット
- Stable Diffusion 3.5のローカル環境構築手順
- Stable Diffusion 3.5 vs 他ツールの比較
- フリーランスの使い分け戦略
- Stable Diffusion 3.5の日本語対応状況
- Stable Diffusion 3.5の活用事例
- Stable Diffusion 3.5の注意点
- こんな人におすすめ
- Stable Diffusion 3.5のFAQ
- Stable Diffusion 3.5の総評
- まとめ:Stable Diffusion 3.5を武器にビジュアル制作の自由度を最大化しよう
- 関連記事
Stable Diffusion 3.5とは?
Stable Diffusion 3.5は、イギリスのStability AI社が2026年にリリースした最新世代のオープンソース画像生成AIモデルです。前バージョン(3.0)から大幅に画質・プロンプト理解力・スタイル制御が向上し、商用有料ツール(Midjourney、DALL-E 3、Adobe Firefly等)と同等の品質を、完全無料かつローカル環境で利用できるという特徴があります。
2026年4月時点で、Stable Diffusion 3.5は以下の3つのモデルバリエーションが公開されています。
- Stable Diffusion 3.5 Large(8Bパラメータ): 最高品質、16GB以上のVRAMが必要
- Stable Diffusion 3.5 Medium(2.5Bパラメータ): 中品質、8GB以上のVRAMで動作
- Stable Diffusion 3.5 Turbo(高速版): 低VRAMでも高速生成、品質は若干低下
筆者はフリーランスのWeb制作者として、クライアント案件のLPビジュアル制作・バナー制作・アイキャッチ画像制作にStable Diffusion 3.5 Largeをローカル環境で運用しています。月額制のMidjourneyやAdobe Fireflyと比較して、ランニングコストがゼロ(電気代とGPU投資のみ)で済む点、生成枚数に制限がない点、画像の商用利用権が明確な点が大きな魅力です。
本記事では、Stable Diffusion 3.5の機能・ローカル環境構築方法・商用利用のポイント・他ツールとの比較まで、フリーランス・個人事業主の実務目線で詳しく解説します。
Stable Diffusion 3.5の主な機能
MMDiT(Multimodal Diffusion Transformer)アーキテクチャ
Stable Diffusion 3.5は、従来のU-Net型からMMDiT型アーキテクチャに進化しました。これにより、テキストと画像の関係理解が飛躍的に向上し、複雑なプロンプトでも意図通りの画像が生成されやすくなっています。
従来モデルでは「赤い帽子を被った青いドレスの女性が緑の傘を持っている」というような複雑な指示が崩れがちでしたが、3.5では各要素の位置関係・色指定が正確に反映されます。
高解像度生成(最大4K)
Stable Diffusion 3.5 Largeは最大4096×4096ピクセル(約4K)の画像を直接生成できます。従来は1024×1024が上限で、高解像度化はアップスケーラーで対応する必要がありましたが、3.5では直接高解像度生成が可能になり、LPのヒーロー画像や印刷物用の高精細画像を一気に生成できます。
プロンプト理解力の向上
Stable Diffusion 3.5はT5-XXLという強力なテキストエンコーダーを採用しており、長文プロンプトの理解力が大幅に向上しています。100単語を超える詳細なプロンプトでも、各要素を忠実に反映した画像を生成できます。
スタイル制御とControlNet対応
特定のアーティスト風・画風・構図を指定できるスタイル制御機能が強化されました。また、ControlNet(構図・ポーズ・深度指定など)にも完全対応し、プロダクション品質のビジュアル制作に耐える柔軟性があります。
LoRA(Low-Rank Adaptation)対応
LoRAという追加学習技術により、特定のスタイルや人物の特徴をモデルに学習させられます。自社ブランドのビジュアルスタイル、キャラクターデザインの一貫性、製品の特徴的な外観など、カスタマイズの可能性は無限です。
Turbo版による高速生成
Stable Diffusion 3.5 Turboは、4ステップ程度の少ない推論回数で生成できる高速モデルです。通常モデルが1枚5〜10秒かかる生成を、1〜2秒で完了します。大量の画像を短時間で試作したい用途で圧倒的に有利です。
Stable Diffusion 3.5の料金
Stable Diffusion 3.5のモデル自体は完全無料でダウンロード・利用できます。Stability AI Community License(コミュニティライセンス)の下で提供されており、以下の条件で商用利用も可能です。
- 年間収益が100万ドル(約1.5億円)未満の個人・中小企業: 商用利用可(無料)
- 年間収益が100万ドル以上の企業: 商用利用には有料ライセンスが必要
個人事業主・フリーランス・中小企業であれば、実質無料で商用利用できます。Midjourney(月額$10〜)やAdobe Firefly(月額$9.99〜)と比較して、ランニングコストは電気代のみで済みます。
ただし、ローカル環境での運用には以下のコストが発生します:
| 項目 | 目安コスト | 備考 |
|---|---|---|
| GPU(NVIDIA RTX 4070以上推奨) | 10〜20万円 | 初期投資、既存PCがあれば不要 |
| 電気代 | 月1,000円〜3,000円 | 利用頻度による |
| ストレージ | 1TB SSD 1万円〜 | モデルファイルで約30GB使用 |
既にゲーミングPCやクリエイター向けPCを持っている人であれば、追加投資はほぼ不要で利用開始できます。
クラウドサービスでStable Diffusion 3.5を使いたい場合は、RunDiffusion、ThinkDiffusion、Replicateなどの選択肢があり、従量課金(1枚あたり$0.01〜$0.05)で利用できます。
Stable Diffusion 3.5のメリット
ランニングコストが電気代だけで済む
月額サブスクリプション型のAI画像生成ツールと比較して、ローカル運用ならランニングコストが電気代のみで済みます。月10,000枚以上を生成するヘビーユーザーほど、月額制ツールとのコスト差が大きくなります。
生成枚数に制限がない
Midjourney(Standardプラン200枚/月)・DALL-E 3(ChatGPT Plus経由で1日50枚)・Adobe Firefly(クレジット制)のような生成上限がありません。思う存分試作・量産ができます。
オフラインで動作する
ローカル環境で動くため、インターネット接続が不要です。機密性の高いプロジェクトや、データ漏洩リスクを避けたい案件でも安心して使えます。特に企業秘密・未公開商品・個人情報を含むビジュアル制作で重要です。
カスタマイズ性が高い
LoRA・ControlNet・カスタムモデルなど、細かいカスタマイズが可能です。自社ブランドに特化したモデルを育てていけば、他社では再現できない独自のビジュアル制作が実現します。
商用ライセンスが明確
Stability AI Community Licenseにより、年収1.5億円未満の個人・中小企業は完全無料で商用利用できます。Midjourneyの「Standardプラン以上で商用利用可」、DALL-E 3の「利用規約に注意」といった曖昧さがなく、安心して使えます。
無料のWeb UIが充実
AUTOMATIC1111、ComfyUI、Forge、InvokeAIなど、無料のWeb UIが豊富に用意されています。初心者でもGUI操作で直感的に利用できる環境が整っています。
Stable Diffusion 3.5のデメリット
セットアップが初心者には難しい
Python環境の構築、依存ライブラリのインストール、モデルファイルのダウンロードなど、初期セットアップに技術的ハードルがあります。完全な初心者がゼロから始めるには、数時間の学習時間が必要です。
GPU投資が必要
快適に使うには、NVIDIA RTX 4070(12GB VRAM)以上のGPUを搭載したPCが必要です。既存PCがなければ、初期投資として10〜20万円の出費が発生します。
電気代がかかる
高負荷でGPUを回すため、一般的なPC利用と比較して電気代が上がります。月数千円程度の増加を見込むべきです。
サポートが自己責任
有料サービスのようなカスタマーサポートはありません。エラーやトラブルは、コミュニティフォーラムや公式Discordで自己解決する必要があります。
画質の安定性では商用ツールに一歩譲る
Midjourney v7・Adobe Firefly 3といった商用最新ツールと比較すると、特定の用途(写実的な人物、アートスタイル)では一歩譲る場面があります。最高品質を求めるプロ案件では、複数ツールの併用が現実的です。
Stable Diffusion 3.5のローカル環境構築手順
フリーランスがローカル環境でStable Diffusion 3.5を使えるようにするまでの手順を解説します。
ステップ1: 必要スペックの確認
最低限のスペックは以下のとおりです。
- OS: Windows 10以降、macOS 12以降、Linux(Ubuntu推奨)
- GPU: NVIDIA RTX 3060(12GB VRAM)以上
- RAM: 16GB以上
- ストレージ: 空き50GB以上
macOSのApple Silicon(M1/M2/M3)でも動作しますが、NVIDIA GPU搭載PCの方が生成速度が速いです。
ステップ2: Python環境の構築
Python 3.10をインストールします。公式サイト(python.org)からダウンロードし、インストール時に「Add Python to PATH」にチェックを入れます。
ステップ3: AUTOMATIC1111またはComfyUIのインストール
初心者にはAUTOMATIC1111(A1111)がおすすめです。GitHub(github.com/AUTOMATIC1111/stable-diffusion-webui)からリポジトリをダウンロードし、README通りにインストールします。より高度な制御をしたい上級者にはComfyUIがおすすめです。
ステップ4: Stable Diffusion 3.5モデルのダウンロード
Hugging Face(huggingface.co/stabilityai)からStable Diffusion 3.5 Largeのモデルファイル(.safetensors形式、約30GB)をダウンロードします。`models/Stable-diffusion/`フォルダに配置します。
ステップ5: 起動と動作確認
`webui.bat`(Windows)または`webui.sh`(Mac/Linux)を実行し、Web UIが立ち上がるのを確認します。ブラウザで`http://127.0.0.1:7860/`にアクセスすると、画像生成画面が表示されます。
ステップ6: 初回生成テスト
プロンプトに「a beautiful landscape with mountains and a lake」のようなシンプルなテキストを入力し、Generateボタンを押して画像が生成されることを確認します。初回は数十秒かかる場合があります。
Stable Diffusion 3.5 vs 他ツールの比較
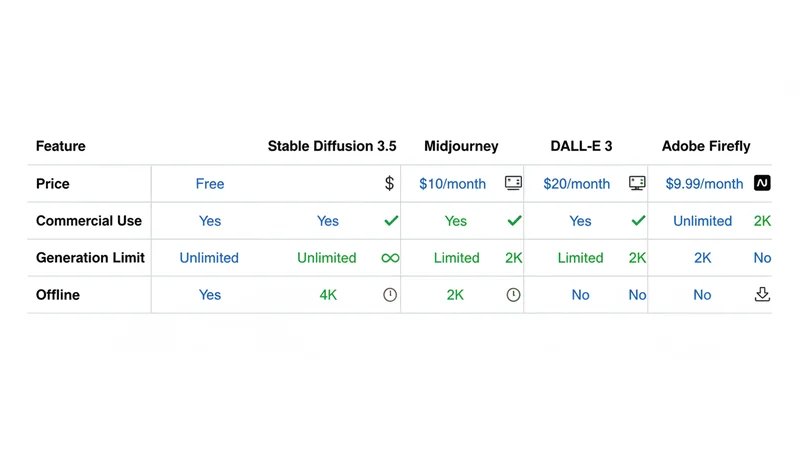
主要な画像生成AIと比較した表が以下です。
| 比較項目 | Stable Diffusion 3.5 | Midjourney v7 | DALL-E 3 | Adobe Firefly 3 |
|---|---|---|---|---|
| 月額料金 | 無料(ローカル) | $10〜 | ChatGPT Plus $20に含む | $9.99〜 |
| 商用利用 | ○(年収1.5億円未満) | ○(Standard以上) | ○ | ○(契約内クレジット内) |
| 生成枚数 | 無制限 | 制限あり | 日50枚 | クレジット制 |
| 最大解像度 | 4K直接生成 | 2K | HD | 2K |
| プロンプト理解力 | 高 | 高 | 高 | 中 |
| カスタムモデル | ○(LoRA等) | × | × | × |
| オフライン動作 | ○ | × | × | × |
| スタイル自由度 | ◎ | ○ | ○ | △ |
| 初期セットアップ | 難 | 易 | 易 | 易 |
| GPU必須 | ○ | × | × | × |
フリーランスの使い分け戦略
案件単価で判断
高単価案件(ブランドビジュアル・CMアート): Midjourney v7 + Stable Diffusion 3.5の併用 中単価案件(LP・バナー): Stable Diffusion 3.5(ローカル) 低単価案件(SNS画像量産): Stable Diffusion 3.5 Turbo(ローカル)
コスト重視なら
月の生成枚数が多く、ランニングコストを抑えたいフリーランスは、Stable Diffusion 3.5のローカル運用が最適です。初期投資(GPU約15万円)を回収した後は、ほぼコストゼロで運用できます。
品質重視なら
最高品質の商用画像を生成したい場合は、Midjourney v7やAdobe Fireflyの方が有利な場面があります。Stable Diffusion 3.5と併用し、用途ごとに使い分けるのが現実的です。
データセキュリティ重視なら
顧客データ・機密情報を扱う案件では、クラウドベースのサービスはデータ漏洩リスクがあります。完全ローカル運用のStable Diffusion 3.5が安全な選択肢です。
Stable Diffusion 3.5の日本語対応状況
プロンプトは英語推奨ですが、T5-XXLエンコーダーにより日本語プロンプトの理解力も大幅に向上しています。筆者の検証では、日本語でも70〜80%の精度で意図を反映した画像が生成されます。
ただし、細かいニュアンスや日本語特有の概念(「侘び寂び」「凛々しい」など)は英語プロンプトの方が正確に反映されます。英訳にはDeepLやChatGPTの活用がおすすめです。
UIは各種Web UI(AUTOMATIC1111・ComfyUI等)で日本語化プラグインが用意されており、英語が苦手でも問題なく操作できます。日本語コミュニティも活発で、Twitter(X)やDiscordで情報交換が盛んです。
Stable Diffusion 3.5の活用事例
事例1: Web制作者のLP画像内製化
LP制作フリーランスが、ヒーロー画像・セクション背景・装飾画像をStable Diffusion 3.5で内製化。従来はストック画像サイトで月5,000円〜1万円支払っていたコストがゼロに、かつオリジナル画像でサイトの独自性が向上しました。
事例2: ECサイト運営者の商品ビジュアル制作
個人店のEC運営者が、商品写真のバックグラウンド合成・シーンイメージ制作にStable Diffusion 3.5を活用。スタジオ撮影コストを月10万円削減し、商品ページの魅力も向上させました。
事例3: ブロガーのアイキャッチ画像量産
月50記事を執筆するブロガーが、アイキャッチ画像をStable Diffusion 3.5 Turboで量産。1枚あたりの制作時間を15分から2分に短縮し、執筆ペースを1.5倍に向上させました。
事例4: YouTuberのサムネイル制作
チャンネル運営者がStable Diffusion 3.5とLoRAを組み合わせ、キャラクターが一貫したサムネイルを量産。ブランディング強化によりCTRが20%向上した事例があります。
事例5: ノベリスト・漫画家の挿絵制作
個人で活動するノベリスト・漫画家が、Stable Diffusion 3.5で挿絵・キャラクター設定画を制作。イラストレーターへの外注コストを削減しつつ、自分の世界観に合ったビジュアルを作り込めるようになりました。
Stable Diffusion 3.5の注意点
商用利用の条件
Stability AI Community Licenseの下での商用利用は、年収1.5億円未満の個人・中小企業に限定されます。年収を超える場合は有料ライセンスの契約が必要です。また、ライセンス条件は将来変更される可能性があるため、利用前に最新のライセンス文書を確認してください。
生成物の著作権
AI生成画像の著作権は、現行法(日本・米国)では人間が創作的寄与をした部分にのみ著作権が発生します。純粋なAI生成画像をそのまま商用利用する場合は、著作権保護を受けられないリスクがあります。重要な案件では、AI生成画像を下敷きに人間が編集・加工するワークフローが安全です。
公序良俗に反する画像への対応
Stable Diffusion 3.5には、暴力的・性的・政治的に問題のある画像生成を抑制するフィルタが組み込まれていますが、完全ではありません。商用案件で使用する前に、生成物が公序良俗に反しないか必ずチェックしてください。
他人の肖像権・商標権への配慮
有名人の顔・ブランドロゴ・キャラクターを生成すると、肖像権・商標権・著作権侵害のリスクがあります。商用案件では、意図せず他人の権利を侵害していないか確認する必要があります。
モデルアップデートによる影響
Stable Diffusionは頻繁にモデルアップデートが行われます。プロジェクト進行中にモデルを更新すると、生成結果が変わってしまう可能性があります。長期プロジェクトでは、使用モデルのバージョンを固定する運用が推奨されます。
こんな人におすすめ
- LP・バナー・アイキャッチなどのビジュアルを大量に内製したいフリーランス
- 月額サブスクリプション型のAI画像生成ツールからコスト削減したい個人事業主
- 機密情報・未公開商品のビジュアル制作でデータ漏洩リスクを避けたいクリエイター
- 独自ブランドのビジュアルスタイルをAIで学習させたいデザイナー
- 画像生成の技術的カスタマイズに挑戦したいエンジニア系フリーランス
- 商用利用時のライセンス条件が明確なツールを選びたいプロ
Stable Diffusion 3.5のFAQ
どのGPUを買えばいいですか?
2026年時点で最もコスパが良いのはNVIDIA RTX 4070(12GB VRAM、約10万円)またはRTX 4080(16GB VRAM、約15万円)です。Stable Diffusion 3.5 Largeを快適に使いたいならRTX 4080以上を推奨します。予算を抑えたい場合はRTX 3060(12GB VRAM、約5万円)でも動作しますが、生成速度は遅くなります。
Apple Silicon(M1/M2/M3)でも動きますか?
動作します。Mac用のAUTOMATIC1111やDiffusionBeeというアプリが対応しています。ただし生成速度はNVIDIA GPUに劣るため、ヘビーユーザーにはNVIDIA GPU搭載のWindows/Linux環境がおすすめです。
Midjourneyからの乗り換えは現実的ですか?
品質面ではMidjourney v7の方が一部のスタイルで上回る場面がありますが、総合的にはStable Diffusion 3.5も十分プロ品質です。コスト重視・大量生成・カスタマイズ重視ならStable Diffusion 3.5への乗り換えは十分ペイします。両方を使い分ける戦略も有効です。
LoRAは自分で作れますか?
作れます。Kohya’s GUIやDiffusers Trainerなどのツールを使えば、20〜50枚の学習画像から独自のLoRAを作成できます。学習には数時間のGPU時間が必要ですが、自分専用のスタイル・キャラクターモデルを作る強力な手段になります。
ローカル以外の実行方法は?
Replicate、RunDiffusion、ThinkDiffusion、Google Colab(有料プラン)などのクラウドサービスでStable Diffusion 3.5を実行できます。GPU投資を避けたい人、出先で使いたい人には現実的な選択肢です。
AUTOMATIC1111とComfyUIどちらがいいですか?
初心者にはAUTOMATIC1111が使いやすく、直感的なUIで基本機能が揃っています。上級者・細かい制御をしたい人にはComfyUIがおすすめで、ノードベースのワークフローで複雑な画像生成パイプラインを組めます。
エラーが出たらどうすればいいですか?
GitHub Issues・Reddit(r/StableDiffusion)・公式Discord・日本語のTwitter(X)コミュニティで情報収集するのが早道です。エラーメッセージをそのまま検索すると、ほぼ解決策が見つかります。
商用案件で納品する前にチェックすべきことは?
生成画像に著名人・実在のブランドロゴ・他人のキャラクターが偶然入っていないか、公序良俗に反する要素がないかを必ずチェックしてください。重要な案件では、AI生成画像を下敷きに人間が加工・編集する工程を挟むと安全です。
Stable Diffusion 3.5の総評
Stable Diffusion 3.5は、2026年時点で最もコストパフォーマンスの高い商用利用可能なAI画像生成ソリューションです。月額サブスクリプション型ツールと異なり、一度環境を整えれば電気代のみで無制限に生成できる経済性、明確な商用利用ライセンス、そして無限のカスタマイズ性は、フリーランス・個人事業主にとって圧倒的な価値を持ちます。
初期セットアップのハードル、GPU投資、自己責任での運用という課題はありますが、これらを乗り越えた先にあるリターンは、年間数十万円のコスト削減と、他社では再現できない独自のビジュアル資産です。
Midjourney・DALL-E 3・Adobe Fireflyのような商用サービスと使い分けながら、Stable Diffusion 3.5をメイン武器に据える。これが2026年のAI画像生成フリーランスの最適解です。
まとめ:Stable Diffusion 3.5を武器にビジュアル制作の自由度を最大化しよう
Stable Diffusion 3.5は、コスト・カスタマイズ性・商用ライセンスの3点で、個人事業主・フリーランスの画像生成ニーズに最も合致するツールです。初期投資としてGPUが必要ですが、月額制ツールと比較して半年〜1年で投資回収できる経済性があります。
まずはRunDiffusionやReplicateなどのクラウドサービスで試し、自分の制作スタイルに合うか検証してください。感触が良ければローカル環境の構築に進み、LoRAやControlNetなど高度な機能を使いこなしていくのがおすすめです。
オープンソースの力を活用して、フリーランスとしての制作力を一段上のレベルに引き上げる。その武器がStable Diffusion 3.5です。
[AFFILIATE_LINK_STABILITY_AI]


コメント